Дмитрий Усенков
Занимательное программирование – игры с текстом
Введение
При изучении в школе основ программирования по какой-то неизвестной авторам данной статьи причине работа с множественными типами данных (кроме разве что массивов и в некоторых случаях – файлов) почти не затрагивается. По крайней мере, найти в различных публикациях или на сайтах образовательной тематики какие-либо хорошие (интересные и вместе с тем поучительные) задачи оказалось довольно сложно.
Желая «сломать сложившиеся стереотипы», предлагаем читателям несколько подобных задач. Решение этих задач разберем на языке Паскаль.
Наши цели при этом:
– во-первых, показать читателям (учащимся, а также учителям информатики, которые смогут затем передать эти знания своим ученикам) принципы обработки строковых данных;
– во-вторых, продемонстрировать применение некоторых возможностей Паскаля по работе со строками и символами;
– в-третьих, показать преимущества использования такого редко используемого типа данных, как множества (как показывает практика, многие попросту не знают, как можно использовать множества в реальном программировании, помимо «чисто теоретического» решения задач на пересечение, объединение и пр. множеств).
Итак, начнем…
О знаках и строках
Как мы знаем из курса информатики, текст в компьютере представлен в виде последовательности кодов составляющих его символов – букв (латинских и строчных), знаков препинания, знаков математических операций и пр., а также специальных кодов, не имеющих отдельного визуального представления в виде символов и служащих для управления размещением текста (пример – коды табуляции, перехода на новую строку и т.д.). При этом соответствие между конкретным символом и его кодом устанавливается согласно таблицам кодирования символов, где для символов национальных алфавитов (к которым относится и кириллица) могут использоваться различные 8-битовые таблицы кодирования (ASCII для MS-DOS, КОИ-8, Windows и др.) либо все такие символы объединены в 16-разрядной таблице кодирования стандарта Unicode.
Таким образом, каждый символ текста в памяти компьютера занимает один (или два – для Unicode) байта и хранится там в виде целого беззнакового числа. Поэтому, чтобы компьютер «не путал» их с обычными целыми числами, в языках программирования высокого уровня, как правило, для символьных и строковых типов данных предназначены отдельные, особые типы данных.
В языке Паскаль это:
– символьный тип char, предназначенный для представления одного какого-либо символа; символьная константа записывается в апострофах, например: 'a', '0', '+' и т.д.;
– множественный (составной, структурированный, сложный) тип string, предназначенный для представления целых текстовых строк; строковая константа также записывается в апострофах, например: 'Строка'.
При этом прослеживается иерархия типов: множественный тип string можно рассматривать как некий набор данных типа char (что отражает вполне очевидный факт – строка текста состоит из символов).
Определение обоих этих типов данных (как и большинства других) в языке Паскаль производится в разделе var:
– для символьного типа данных – var <переменная> : char;
– для строкового типа данных – var <переменная> : string;
При этом строка может определяться как без указания ее размера (как продемонстрировано выше), так и с явным указанием ее длины (см. рис. 1):
var <переменная> : string[<длина>];
В подобном случае параметр <длина> представляет собой целое число, указывающее максимально допустимую длину строки, записываемой в такую переменную. Фактически же этот параметр указывает компьютеру, что для хранения такой переменной необходимо отвести указанное количество ячеек памяти для символов строки. Кроме них, в памяти также резервируется еще одна ячейка для хранения реальной длины строки, записанной в такую переменную: эта строка по длине может быть меньше, чем зарезервированная длина строковой переменной (и даже может быть пустой – не содержать символов вообще!), тогда часть зарезервированных ячеек памяти попросту не используется. А вот при попытке записать в строковую переменную значение (строку), длина которой превышает объявленную длину строковой переменной, приведет к тому, что в этой переменной уместится только заявленное количество символов начала строки, а всё остальное будет отброшено.
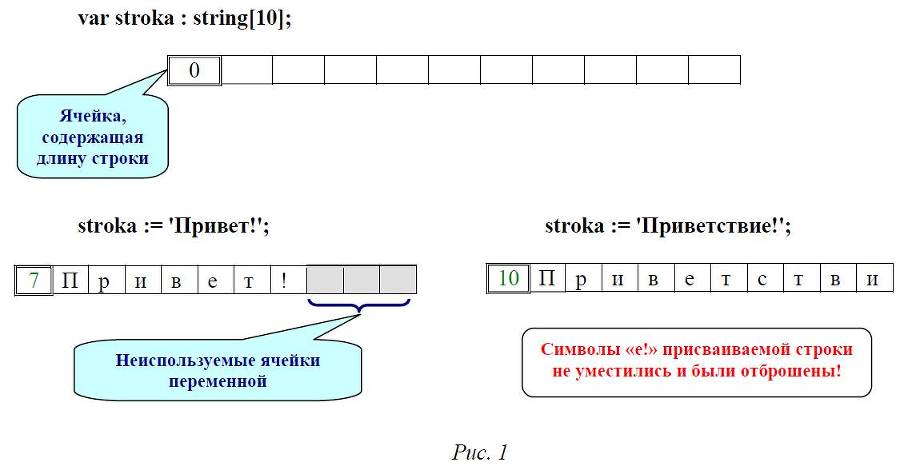
Следует также отметить, что в случае, когда мы не указываем размер определяемой в разделе var строковой переменной, его всё равно определяет сама система программирования. В этом случае максимально допустимая длина строки составляет 255 символов, т.е. в памяти компьютера под такую строковую переменную резервируется 256 ячеек (одна, как и раньше, для хранения реальной длины хранящегося в этой переменной строкового значения). Все рассуждения о ситуациях, когда такой переменной присваивается более короткая или, наоборот, более длинная строка, тоже при этом остаются в силе.
Массивы символов и строк в языке Паскаль также возможны. Их определение и работа с ними осуществляются точно так же, как и с массивами чисел. Например, для описания одномерных массивов можно использовать команды:
– массив символов – var <имя массива> : array[<кол-во элементов>] of char;
– массив строк – var <имя массива> : array[<кол-во элементов>] of string;
При этом для строковых массивов можно после обозначения типа string, как и в случае простой строки, указать значение размера этих строк (все строки массива, разумеется, должны иметь одинаковый максимально допустимый размер).
Обращение же к элементам таких массивов производится полностью аналогично обращению к элементам числовых массивов – путем указания имени массива и записанного после него в квадратных скобках индекса элемента.
А теперь – внимание! – начинается самое интересное.
В отличие, например, от Бейсика, где строки рассматриваются как «единое целое», в языке Паскаль (а также в ряде других языков, например, в Си) существует дуализм представления строк: к любой строке, определенной как тип string, можно в программе обращаться и как к единому целому (к переменной типа string), и как к одноименному одномерному массиву символов, указывая после имени строковой переменной в квадратных скобках номер (индекс) желаемого символа в строке! (При этом следует помнить, что символы в строках всегда нумеруются с единицы.)
Например, если мы определили строковую переменную оператором
var stroka : string[10];
и записали в нее строку 'Привет!', то оператор
writeln(stroka[1]);
выведет на экран символ 'П', а оператор
writeln(stroka[7]);
выведет символ восклицательного знака.
Соответственно, одномерный массив строк можно аналогичным образом рассматривать как двумерный массив символов, двумерный массив строк – как трехмерный массив символов и т.д.
Эта замечательная возможность делает ненужным использование функций извлечения символа из строки (типа MID$(<имя строки>,<позиция символа>,1) в Бейсике), поскольку для получения нужного символа достаточно просто обратиться к нему напрямую. Насколько это упрощает решение некоторых задач на работу со строками, мы увидим, когда перейдем к решению таких задач.