Это соображение привело к созданию протокола HTTP 1.1, который поддерживал постоянные соединения (persistent connection). Это означало, что появилась возможность установки TCP-соединения, отправки запроса, получения ответа, а затем передачи и приема дополнительных запросов и ответов. Эта стратегия называется повторным использованием соединения (connection reuse). Таким образом, снизились накладные расходы, возникавшие при постоянных установках и разрывах соединения. Стало возможным также конвейеризировать запросы, то есть отправлять запрос 2 еще до прибытия ответа на запрос 1.
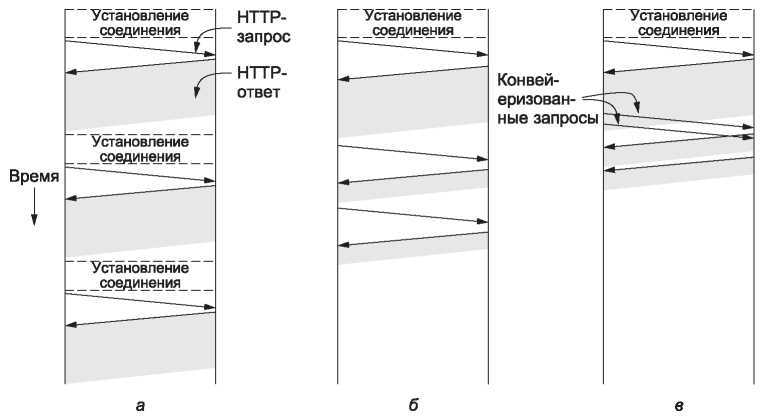
Разница в производительности между этими тремя случаями показана на рис. 7.16. В части а мы видим три запроса, отсылаемых один за другим, при этом для каждого устанавливается отдельное соединение. Предположим, что это представление страницы с двумя размещенными на ней картинками, находящимися на одном сервере. URL изображений определяется при получении главной страницы, так что они получаются позднее ее. Сегодня на обычной странице присутствует около 40 других объектов, которые должны быть получены для ее отображения. Но это сделает наш рисунок огромным. Так что в нашем примере мы используем всего два размещенных объекта.
Рис. 7.16. HTTP: а — множественные соединения и последовательные запросы; б — постоянное соединение и последовательные запросы; в — постоянное соединение и конвейеризованные запросы
На рис. 7.16, б страница получена при помощи постоянного соединения. То есть TCP-соединение открывается с самого начала, затем посылаются те же самые 3 запроса, как и раньше один за другим, и только после этого соединение закрывается. Заметьте, что загрузка завершается быстрее. Это происходит по двум причинам: во-первых, не тратится время на установку дополнительных соединений. Для каждого TCP-соединения требуется дополнительное время, как минимум, для его подтверждения. Во-вторых, передача тех же картинок проходит быстрее. Спросите, почему? Все это из-за контроля перегрузок сети в TCP. Сразу после установки соединения TCP использует процедуру медленного старта, чтобы увеличить пропускную способность, пока он не изучит поведение сетевого пути. Вследствие этого периода «разогрева» на передачу информации посредством множественных коротких TCP-соединений уходит гораздо больше времени, чем в случае с использованием одного длительного TCP-соединения. Наконец, на рис. 7.16, в установлено одно постоянное соединение, а запросы передаются конвейеризовано. Второй и третий запросы отсылаются за особенно короткий промежуток времени, так как была получена достаточно большая часть главной страницы, чтобы можно было сделать вывод о том, что изображения должны быть загружены и отображены. В итоге приходят ответы на эти запросы. Этот метод сокращает время, в течение которого сервер не занят делом, так что он и дальше повышает производительность. Однако за постоянные соединения приходится платить. Новый вопрос, который возникает вокруг них, — это «когда закрывать соединение?» Соединение с сервером не должно разрываться, пока загружается страница. А что потом? Высок шанс того, что пользователь нажмет на ссылку, которая запросит еще одну страницу с сервера. Если соединение остается открытым, следующий запрос может быть отослан немедленно. Однако нет гарантии того, что клиент создаст запрос к серверу в ближайшее время. На практике клиенты и серверы обычно сохраняют постоянное соединение, пока не пройдет какого-то небольшого промежутка времени (например, 60 с), в течение которого не будет отослано ни одного запроса и не будет принято ни одного ответа, или же в том случае, если открыто слишком много соединений и некоторые следует закрыть.
Внимательный читатель мог заметить, что существует одна комбинация, о которой мы пока не упомянули. Можно также посылать один запрос по одному TCP-соединению, но устанавливать эти соединения параллельно. Этот метод параллельных соединений (parallel connection) широко использовался браузерами до появления постоянных соединений. И у него тот же недостаток, что и у последовательных соединений — дополнительные служебные операции, — но производительность гораздо выше. Так происходит из-за того, что параллельная установка и увеличение количества соединений скрадывает некоторое количество времени. В нашем примере соединения для обоих размещенных изображений могут быть установлены в одно и то же время. Однако запуск большого числа TCP-соединений с одним и тем же сервером — не лучшая идея. Причина кроется в том, что TCP реализует отслеживание перегрузок отдельно для каждого соединения. В результате соединения соревнуются друг с другом, вызывая дополнительные потери пакетов, и в сочетании являются более агрессивными пользователями сети, чем индивидуальные соединения. Постоянные соединения стоят на уровень выше и их использование более предпочтительно, чем использование параллельных, так как они избегают ненужных издержек и не страдают от проблем с перегрузками.
Методы
Несмотря на то что HTTP был разработан специально для использования в вебтехнологиях, он был намеренно сделан более универсальным, чем это было необходимо, так как рассчитывался на будущее применение в объектно-ориентированных приложениях. По этой причине в дополнение к обычным запросам веб-страниц были разработаны специальные операции, называемые методами. Они обязаны своим существованием технологии SOAP.
Каждый запрос состоит из одной или нескольких строк ASCII-текста, причем первое слово в первой строке является именем вызываемого метода. Встроенные методы перечислены в табл. 7.12. Имена методов чувствительны к регистру символов, то есть метод GET существует, а get — нет.
Таблица 7.12. Встроенные методы HTTP-запросов
Метод GET запрашивает у сервера страницу (под которой в общем случае подразумевается объект, но на практике обычно это просто файл), закодированную согласно стандарту MIME. Большую часть запросов к серверу составляют именно запросы GET. Вот самая типичная форма GET:
GET filename HTTP/1.1
где filename указывает на запрашиваемую страницу, а 1.1 — на используемую версию протокола.
Метод HEAD просто запрашивает заголовок сообщения, без самой страницы. С помощью этого метода можно собрать индексную информацию или просто проверить работоспособность данного URL.
Метод POST используется, когда подтверждаются формы. Он, так же как и метод GET, используется для веб-сервисов SOAP. В нем также хранится URL, но вместо того, чтобы просто найти страницу, он передает данные на сервер (то есть содержимое формы или параметры RPC). Затем сервер в зависимости от URL что-то делает с этими данными, обычно прикрепляет их к объекту. В результате может быть, к примеру, что-то продано или вызвана процедура. Наконец, метод возвращает страницу с полученным результатом.
Оставшиеся методы редко используются для просмотра сетевых ресурсов. Метод PUT является противоположностью метода GET: он не читает, а записывает страницу.
Этот метод позволяет создать набор веб-страниц на удаленном сервере. Тело запроса содержит страницу. Она может быть закодирована с помощью MIME. В этом случае строки, следующие за командой PUT, могут включать различные заголовки, например заголовки аутентификации, подтверждающие права абонента на запрашиваемую операцию.
Метод DELETE, что неудивительно, удаляет страницу или, по крайней мере, указывает на то, что веб-сервер удалит страницу. Как и в методе PUT, здесь особую роль могут играть аутентификация и разрешение на выполнение этой операции.
Метод TRACE предназначен для отладки. Он приказывает серверу отослать назад запрос. Этот метод особенно полезен, когда запросы обрабатываются некорректно и клиенту хочется узнать, что за запрос реально получает сервер.