Каждая зона также ассоциируется с одним или более сервером имен. Это хосты, на которых находится база данных для зоны. Обычно у зоны есть один основной сервер имен, который получает информацию из файла на своем диске, и один или более второстепенных серверов имен, получающих информацию с основного сервера имен. Для повышения надежности некоторые серверы имен могут быть расположены вне зоны.
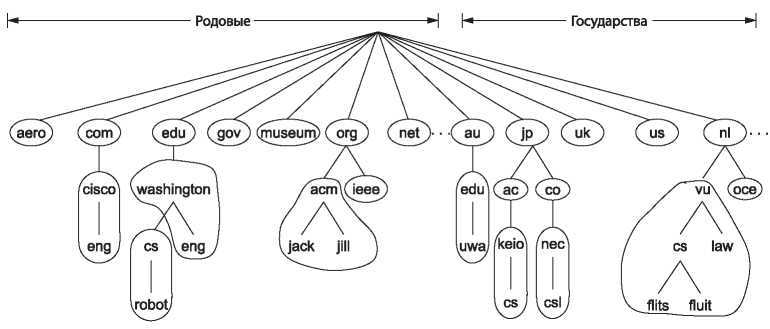
Рис. 7.2. Часть пространства имен DNS, разделенная на очерченные зоны
Процесс поиска адреса по имени называется разрешением имен (name resolution). Распознаватель обращается с запросом разрешения имени домена к локальному серверу имен. Если искомый домен относится к сфере ответственности данного сервера имен, как, например, домен top.cs.vu.nl подпадает под юрисдикцию домена cs.vu.nl, тогда данный DNS-сервер сам отвечает распознавателю на его запрос, передавая ему авторитетную запись (authoritative record) ресурса. Авторитетной называют запись, получаемую от официального источника, хранящего данную запись и управляющего ее состоянием. Поэтому такая запись всегда считается верной, в отличие от кэшируемых записей (cached records), которые могут устаревать.
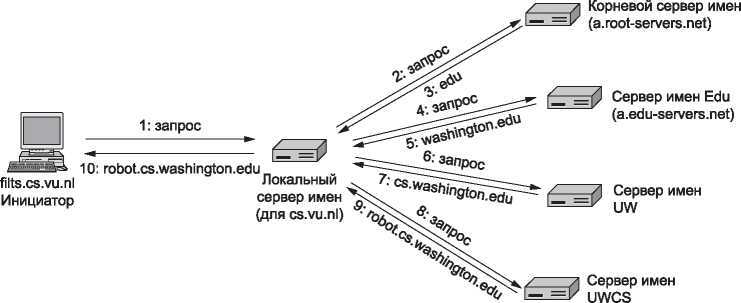
Однако что происходит, если домен удаленный, как, например, в случае, когда flits.cs.vu.nl пытается найти IP-адрес для robot.cs.washington.edu в Вашингтонском университете? В этом случае, если в кэше нет информации о запрашиваемом домене, доступном локально, сервер имен посылает удаленный запрос. Поясним данный процесс на примере, показанном на рис. 7.3. На первом шаге (обозначен «1») посылается запрос локальному серверу имен. Этот запрос содержит имя искомого домена, тип (Л) и класс (IN).
Рис. 7.3. Пример поиска распознавателем имени удаленного хоста в десяти шагах
На следующем шаге посылается запрос на один из корневых серверов имен (root name servers), находящихся на вершине иерархии. На этих серверах имен хранится информация о каждом домене высшего уровня. Этот запрос показан как шаг 2 на рис. 7.3. Чтобы связаться с корневым сервером, на каждом сервере имен должна быть информация об одном или более корневых серверах имен. Обычно эта информация представлена в файле системной конфигурации, который загружается в кэш DNS, когда запускается сервер DNS. Он является просто списком записей NS и соответствующих записей А.
Существует 13 корневых серверов DNS, которые называются незамысловато — от a-root-servers.net до m.root-servers.net. Каждый корневой сервер логически мог бы быть отдельным компьютером. Однако так как весь Интернет зависит от корневых серверов, они являются мощными машинами, а информация, хранящаяся на них, неоднократно дублируется. Большинство серверов расположено в различных географических точках, и доступ к ним осуществляется посредством адресации любому устройству из группы, при этом пакет доставляется на ближайший адрес (мы описали адресацию любому устройству группы в пятой главе). Дублирование информации повышает надежность и производительность.
Маловероятно, чтобы этот корневой сервер имен знал адрес машины в Вашингтонском университете. Скорее всего, он даже не знает адреса сервера имен самого университета, однако он должен знать сервер имен домена edu, на котором расположен cs.washington.edu. Он возвращает имя и IP-адрес для части ответа на третьем шаге.
Далее локальный сервер имен продолжает этот сложный путь. Он направляет запрос серверу имен edu (a.edu-servers.net), который выдает имя сервера Вашингтонского университета. Этот процесс проиллюстрирован шагами 4 и 5. Теперь мы уже подошли ближе. Локальный сервер имен отсылает запрос на сервер имен Вашингтонского университета (шаг 6). Если искомое имя домена находится на факультете английского языка, будет получен ответ, так как зона университета этот факультет охватывает. Но факультет вычислительной техники решил запустить собственный сервер имен. Запрос возвращает имя и IP-адрес сервера имен факультета вычислительной техники Вашингтонского университета (шаг 7).
Наконец, локальный сервер имен запрашивает сервер имен факультета вычислительной техники Вашингтонского университета (шаг 8). Этот сервер отвечает за домен cs.washington.edu, так что он должен выдать ответ. В итоге окончательный ответ возвращается (шаг 9), и локальный сервер имен передает его на flits.cs.vu.nl (шаг 10). Имя получено.
Вы можете изучить этот процесс, используя стандартные программы типа dig, которые установлены на большинстве UNIX-систем. Например, напечатав dig @a.edu-servers.net robot.cs.washington.edu
вы отправите запрос robot.cs.washington.edu на сервер имен a.edu-servers.net и получите распечатку результата. Так вы увидите информацию, которую мы получили на четвертом шаге в нашем примере, и узнаете имя и IP-адреса серверов имен Вашингтонского университета.
В этом длинном сценарии есть три технических момента, требующих пояснения. Во-первых, на рис. 7.3 используется два разных механизма запроса. Когда хост flits. cs.vu.nl отсылает запрос на локальный сервер имен, этот сервер выполняет запрос от имени flits, пока не получит ответ, который можно будет вернуть. Он не возвращает частичных ответов. Они могут быть полезными, но в запросе о них нет ни слова. Этот механизм называется рекурсивным запросом (recursive query).
С другой стороны, корневой сервер имен (и каждый последующий) не продолжает рекурсивно запрос локального сервера имен. Он возвращает лишь частичный ответ и переходит к следующему запросу. Локальный сервер имен отвечает за продолжение поиска ответа, направляя следующие запросы. Этот механизм называется итеративным запросом (iterative query).
В одном процессе поиска имени могут быть задействованы оба механизма, как показано в этом примере. Рекурсивные запросы практически всегда кажутся предпочтительными, но многие серверы имен (особенно корневые) их не обрабатывают. Они слишком загружены. Итеративные запросы накладывают груз обработки запроса на ту машину, которая их порождает. Для локального сервера имен разумно поддерживать рекурсивные запросы, чтобы предоставлять сервис хостам на своем домене. Эти хосты не обязательно должны быть сконфигурированы таким образом, чтобы обегать все серверы имен, им нужна лишь возможность обратиться к локальному.
Второе, на чем стоит заострить внимание, — это кэширование. Все ответы, в том числе все возвращенные частичные ответы, сохраняются в кэше. Таким образом, если другой хост cs.vu.nl запрашивает robot.cs.washington.edu, ответ будет уже известен. Более того, если хост запрашивает другой хост на том же домене, например galah. cs.washington.edu, ответ может быть отослан напрямую на сервер имен, который отвечает за это имя. Сходным образом запросы на другие домены на washington.edu могут начинаться напрямую с сервера имен washington.edu. Использование ответов, сохраненных в кэше, серьезно сокращает количество шагов в запросе и повышает производительность. Сценарий, который мы набросали, на самом деле, является худшим из возможных вариантов, так как в кэше нет полезной информации.
Однако ответы, сохраненные в кэше, не являются авторитетными, так как изменения в домене cs.washington.edu не будут распространяться автоматически на все кэши, в которых может храниться копия этой информации. По этой причине записи кэша обычно долго не живут. В каждой записи ресурса присутствует поле Time_to_live. Оно сообщает удаленным серверам, насколько долго следует хранить эту запись в кэше. Если какая-либо машина сохраняет постоянный адрес годами, возможно, будет достаточно надежно хранить эту информацию в кэше в течение одного дня. Для более непостоянной информации, вероятно, более осмотрительно удалять все записи через несколько секунд или одну минуту3.