В Интернете TCP является незаменимым в процессе контроля перегрузки, так же как и при транспортировке данных.
Общие вопросы, касающиеся контроля перегрузки, мы уже обсуждали в разделе 6.3. Основная мысль заключалась в следующем: транспортный протокол, использующий закон управления AIMD (Additive Increase Multiplicative Decrease, аддитивное увеличение мультипликативное уменьшение) при получении двоичных сигналов сети о перегрузке, сходится к справедливому и эффективному распределению пропускной способности. Контроль перегрузки в TCP реализует этот подход с помощью окна, а в качестве сигнала используется потеря пакетов. В каждый момент времени в сети может находиться не более чем фиксированное число байт от каждого отправителя. Это число байт составляет размер окна перегрузки. Соответственно, скорость отправки равна размеру окна, деленному на круговую задержку соединения. Размер окна задается в соответствии с правилом AIMD.
Как вы наверняка помните, помимо окна перегрузки существует также окно управления потоком, определяющее число байт, которое получатель может поместить в буфер. Оба эти параметра играют важную роль: число байт, которое отправитель может передать в сеть, равно размеру меньшего из этих окон. Таким образом, эффективное окно — меньшее из того, что устраивает отправителя, и того, что устраивает получателя. Здесь необходимо участие обеих сторон. TCP остановит отправку данных, если одно из окон временно окажется заполненным. Если получатель говорит: «Посылайте 64 Кбайт», но отправитель знает, что если он пошлет более 32 Кбайт, то в сети образуется затор, он посылает все же 32 Кбайт. Если же отправитель знает, что сеть способна пропустить и большее количество данных, например 128 Кбайт, он передаст столько, сколько просит получатель (то есть 64 Кбайт). Окно управления потоком было описано ранее, поэтому в дальнейшем мы будем говорить только об окне перегрузки.
Современная схема контроля перегрузки была реализована в TCP во многом благодаря стараниям Ван Джекобсона (Van Jacobson, 1988). Это поистине захватывающая история. Начиная с 1986 года рост популярности Интернета привел к возникновению ситуаций, которые позже стали называть отказом сети из-за перегрузки (congestion collapse), — длительных периодов, во время которых эффективная пропускная способность резко падала (более чем в 100 раз) из-за перегрузки сети. Джекобсон (и многие другие) решил разобраться в ситуации и придумать конструктивное решение.
В результате Джекобсону удалось реализовать решение высокого уровня, которое состояло в использовании метода AIMD для выбора окна перегрузки. Особенно интересно то, что при всей сложности контроля перегрузки в TCP он смог добавить его в уже существующий протокол, не изменив ни одного формата сообщений. Благодаря этому новое решение можно было сразу применять на практике. Сначала Джекобсон заметил, что потеря пакетов является надежным сигналом перегрузки, даже несмотря на то, что эта информация и приходит с небольшим опозданием (уже после возникновения перегрузки). В конце концов, трудно представить себе маршрутизатор, который не удаляет пакеты при перегрузке. И в дальнейшем это вряд ли изменится. Даже когда буферная память будет исчисляться терабайтами, скорость сетей, скорее всего, также возрастет до нескольких терабит в секунду.
Здесь есть одна тонкость. Дело в том, что использование потери пакетов в качестве сигнала перегрузки предполагает, что ошибки передачи происходят сравнительно редко. В случае беспроводных сетей (например, 802.11) это не так, поэтому в них используются свои собственные механизмы повторной передачи данных на канальном уровне. Из-за особенностей повторной передачи в беспроводных сетях потеря пакетов на сетевом уровне, вызванная ошибками передачи, обычно не учитывается. В сетях, использующих провода и оптоволоконные линии, частота ошибок по битам, как правило, низкая.
Все алгоритмы TCP для Интернета основаны на том предположении, что пакеты теряются из-за перегрузок. Поэтому они внимательно следят за тайм-аутами и пытаются обнаружить любые признаки проблемы подобно тому, как шахтеры следят за своими канарейками. Чтобы узнавать о потере пакетов вовремя и с высокой точностью, необходим хороший таймер повторной передачи. Мы уже говорили о том, как таймеры повторной передачи в TCP учитывают среднее значение и отклонение круговой задержки. Усовершенствование таких таймеров за счет учета отклонений стало важным шагом в работе Джекобсона. Если время ожидания повторной передачи выбрано правильно, TCP-отправитель может следить за количеством исходящих байт, нагружающих сеть. Для этого ему необходимо просто сравнить порядковые номера переданных и подтвержденных пакетов.
Теперь наша задача выглядит вполне простой. Все, что нам нужно, — это следить за размером окна перегрузки (с помощью порядковых номеров и номеров подтверждений) и изменять его, следуя правилу AIMD. Но, как вы уже догадались, на самом деле все гораздо сложнее. Первая сложность заключается в том, что способ отправки пакетов в сеть (даже за короткие промежутки времени) должен зависеть от сетевого пути. Иначе возникнет затор. Для примера рассмотрим хост с окном насыщения 64 Кбайт, подключенный к коммутируемой сети Ethernet со скоростью 1 Гбит/с. Если хост отправит целое окно за один раз, всплеск трафика может пойти через медленную ADSL-линию (1 Мбит/с). Этот трафик, прошедший по гигабитной линии за половину миллисекунды, на целых полсекунды парализует работу медленной линии, полностью блокируя такие протоколы, как VoIP. Так может работать протокол, нацеленный на создание перегрузок, но не на борьбу с ними.
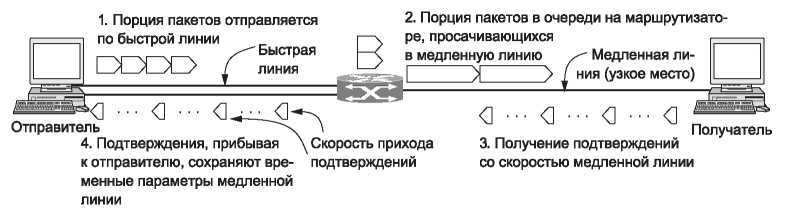
Однако отправка небольших порций пакетов может оказаться полезной. На рис. 6.37 показано, что произойдет, если хост-отправитель, подключенный к быстрой линии (1 Гбит/с), отправит небольшую порцию пакетов (4) получателю, находящемуся в медленной сети (1 Мбит/с), которая является узким местом пути или его самой медленной частью. Сначала эти 4 пакета будут перемещаться по сети с той скоростью, с которой они будут отправлены. Затем маршрутизатор поместит их в очередь, так как они будут прибывать по высокоскоростной линии быстрее, чем передаваться по медленной линии. Но эта очередь не будет длинной, поскольку число пакетов, отправленных за один раз, невелико. Обратите внимание на то, что на рисунке пакеты, проходящие по медленной линии, выглядят длиннее, так как для их отправки требуется больше времени, чем по быстрой линии.
Наконец, пакеты попадают на приемник, где подтверждается их получение. Время отправки подтверждения зависит от времени прибытия пакета по медленному каналу. Поэтому на обратном пути расстояние между пакетами будет больше, чем в самом начале, когда исходные пакеты перемещались по быстрому каналу. Оно не изменится на протяжении всего прохождения подтверждений через сеть и обратно.
Рис. 6.37. Порция пакетов, переданная отправителем, и скорость прихода подтверждений
Здесь особенно важно следующее: подтверждения прибывают к отправителю примерно с той же скоростью, с которой пакеты могут передаваться по самому медленному каналу пути. Именно эта скорость и нужна отправителю. Если он будет передавать пакеты в сеть с такой скоростью, они будут перемещаться настолько быстро, насколько позволяет самый медленный канал, но зато не будут застревать в очередях на маршрутизаторах. Такая скорость называется скоростью прихода подтверждений (ack clock) и является неотъемлемой частью TCP. Этот параметр позволяет TCP выровнять трафик и избежать ненужных очередей на маршрутизаторах.
Вторая сложность состоит в том, что достижение хорошего рабочего режима по правилу AIMD в быстрых сетях потребует очень большого времени, если изначально выбрано маленькое окно перегрузки. Рассмотрим средний сетевой путь, позволяющий передавать трафик со скоростью 10 Мбит/с и круговой задержкой 100 мс. В данном случае удобно использовать окно перегрузки, равное произведению пропускной способности и времени задержки, то есть 1 Мбит или 100 пакетов по 1250 байт. Если изначально взять окно размером один пакет и увеличивать это значение на один пакет через интервал времени, равный круговой задержке, соединение начнет работать с нормальной скоростью только через 100 круговых задержек, то есть через 10 с. Это слишком долго. Теоретически мы могли бы начать с большего окна — скажем, размером 50 пакетов. Но для медленных линий это значение будет слишком большим. Тогда при отправке 50 пакетов за один раз возникнет затор — о таком сценарии мы говорили выше.