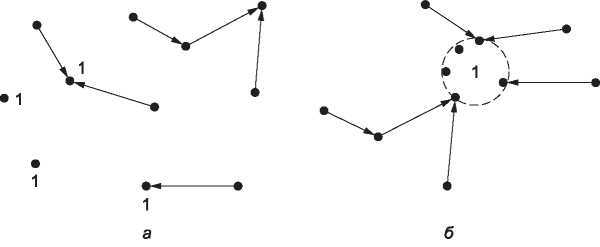
Усечение позволяет строить эффективные связующие деревья, состоящие только из тех связей, которые необходимы для соединения с членами группы. Недостаток данного метода заключается в том, что он требует от маршрутизаторов выполнения большого количества операций, особенно в больших сетях. Предположим, что в сети есть n групп, каждая из которых в среднем состоит из m членов. На каждом маршрутизаторе и для каждой группы должно храниться m усеченных связующих деревьев, то есть mn деревьев для всей сети. К примеру, на рис. 5.14, в изображено связующее дерево, по которому самый левый маршрутизатор отправляет пакеты группе 1. Связующее дерево, по которому самый правый маршрутизатор отправляет пакеты группе 1 (оно не показано на рисунке), будет выглядеть по-другому, поскольку пакеты будут передаваться непосредственно членам группы, а не через узлы в левой части графа. А это значит, что выбор направления, в котором маршрутизаторы должны передавать пакеты для группы 1, зависит от того, какой узел является отправителем. При большом количестве групп и отправителей для хранения всех деревьев потребуется много памяти.
Альтернативный метод при построении отдельного связующего дерева для группы использует деревья с корнем в ядре (core-based trees)(Ballardie и др., 1993). Согласно этому методу, все маршрутизаторы выбирают общий корень (также называемый ядром — core или точкой встречи — rendezvouz point), а для построения дерева все члены группы отправляют в этот корень специальный пакет. Конечное дерево формируется из путей, пройденных этими пакетами. На рис. 5.15, а показано такое дерево с основанием в ядре, построенное для группы 1. Для пересылки пакета этой группе отправитель передает сообщение ядру, откуда оно уже рассылается по дереву. Пример такой работы алгоритма продемонстрирован на рис. 5.15, б для отправителя, расположенного в правой части сети. Однако производительность этого метода может быть улучшена: дело в том, что для многоадресной рассылки не обязательно, чтобы пакеты, предназначенные для группы, приходили в ядро. Как только пакет достигает дерева, он может быть передан как в направлении корня, так и в любом другом направлении. Так алгоритм работает для отправителя, расположенного вверху рис. 5.15, б.
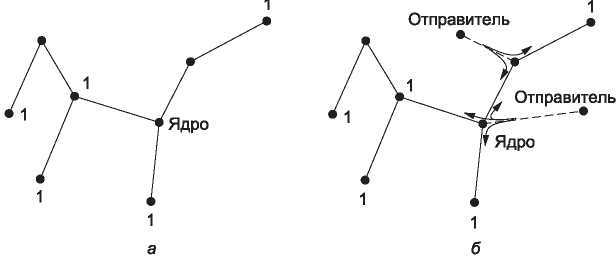
Рис. 5.15. Дерево с основанием в сердцевине для группы 1 (а); рассылка для группы 1 (б)
Использование общего дерева не является оптимальным для всех источников. В примере на рис. 5.15, б пакет, передаваемый от отправителя, расположенного в правой части сети, правому верхнему члену группы не напрямую, а через ядро, требует трех переходов. Степень неэффективности зависит от взаимного расположения ядра и отправителей, но чаще всего разумно располагать ядро посередине между отправителями. Если отправитель всего один (как, например, при трансляции видеозаписи членам группы), оптимальной идеей является использовать в качестве ядра самого отправителя.
Следует также отметить, что использование общего дерева позволяет существенно снизить затраты на хранение информации, а также уменьшить число отправленных сообщений и объем вычислений. Для каждой группы маршрутизатор должен хранить не m деревьев, а лишь одно. Кроме того, маршрутизаторы, не являющиеся частью дерева, не участвуют в передаче сообщений группе. Поэтому алгоритмы на основе общих деревьев (в частности, деревьев с основанием в ядре) используются при широковещании для разреженных групп в сети Интернет, являясь частью популярных протоколов, таких как PIM (Protocol Independent Multicast — многоадресная рассылка, не зависящая от протокола) (Fenner и др., 2006).
5.2.9. Произвольная маршрутизация
До сих пор мы рассматривали такие модели предоставления информации, в которых источник отправляет сообщение на один адрес (одноадресная рассылка — unicast), на все адреса (широковещание) или группе адресов (многоадресная рассылка). Иногда используется еще одна модель под названием произвольная рассылка (anycast). При такой рассылке пакет отправляется ближайшему члену группы (Partridge и др., 1993). Методы нахождения соответствующих путей называются произвольной маршрутизацией (anycast routing).
Зачем нам может понадобиться произвольная рассылка? Иногда узлы предоставляют услугу (например, сообщают время суток или передают контент), для которой важно одно: чтобы информация была правильной; при этом не имеет значения, какой узел ее предоставил — с этой задачей справился бы любой узел. Пример использования свободной рассылки в сети Интернет — DNS, о которой мы поговорим в главе 7.
К счастью, нам не придется придумывать новые алгоритмы для произвольной маршрутизации: стандартные методы — маршрутизация по вектору расстояния и маршрутизация с учетом состояния линий — позволяют создавать маршруты для произвольной рассылки. Предположим, что нам нужно передать данные членам группы 1. Вместо различных адресов все члены группы получат одинаковый адрес — «1». Алгоритм маршрутизации по вектору расстояния распределит векторы обычным способом, и узлы выберут кратчайший путь к адресу 1. В результате узлы отправят данные на ближайшее устройство с адресом 1. Соответствующие маршруты показаны на рис. 5.16 а. Этот метод работает успешно потому, что протокол маршрутизации не знает о существовании нескольких устройств с адресом 1, а значит, он считает их всех одним узлом, как показано в топологии на рис. 5.16, б.
Рис. 5.16. Произвольная маршрутизация: а — маршруты для свободной рассылки; б — топология с точки зрения протокола маршрутизации
Такой метод будет работать и для маршрутизации с учетом состояния линий. Здесь, правда, следует добавить, что протокол маршрутизации не обязательно должен находить кажущиеся кратчайшими пути, проходящие чрез узел 1. Это привело бы к «прыжку через гиперпространство», потому что экземпляры узла 1 на самом деле расположены в различных частях сети. Однако сейчас протоколы маршрутизации с учетом состояния линий различают маршрутизаторы и хосты. Мы не говорили об этом раньше, поскольку в этом не было явной необходимости.
5.2.10. Алгоритмы маршрутизации для мобильных хостов
Миллионы людей пользуются компьютерами на ходу. Сюда относятся ситуации фактического передвижения, такие как использование беспроводных устройств в движущемся автомобиле, а также ситуации мобильного использования портативных компьютеров в нескольких разных местах. Термин мобильные хосты (mobile hosts) мы будем использовать для обозначения и тех, и других ситуаций, противопоставляя их стационарным, никогда не перемещающимся хостам. В последнее время люди все больше хотят оставаться в сети независимо от того, в какой части земного шара они находятся, и делать это так же легко, как дома. Такие мобильные хосты вызывают дополнительную сложность: чтобы направить пакет к мобильному хосту, сеть должна сначала найти его.
Здесь мы будем рассматривать модель мира, в которой у всех хостов есть постоянное домашнее местоположение (home location), которое никогда не меняется. У каждого хоста также есть постоянный домашний адрес, которым можно воспользоваться для определения домашнего местоположения, аналогично тому, как телефонный номер 1-212-5551212 обозначает США (страна с кодом 1) и Манхеттен (212). Целью маршрутизации в системах с мобильными хостами является обеспечение возможности передачи пакетов мобильным хостам с помощью их постоянных домашних адресов. При этом пакеты должны эффективно достигать хостов, независимо от их расположения. Самое сложное здесь, конечно, — найти хост.
Следует сказать несколько слов об этой модели. Существует такой вариант: можно заново вычислять маршруты каждый раз при смене местоположения хоста или при изменении топологии. Тогда можно было бы просто воспользоваться алгоритмами маршрутизации, описанными ранее в этом разделе. Однако, учитывая, насколько быстро увеличивается количество хостов, становится ясно: в результате вся сеть будет бесконечно занята вычислением новых маршрутов. Использование домашних адресов значительно упрощает задачу.