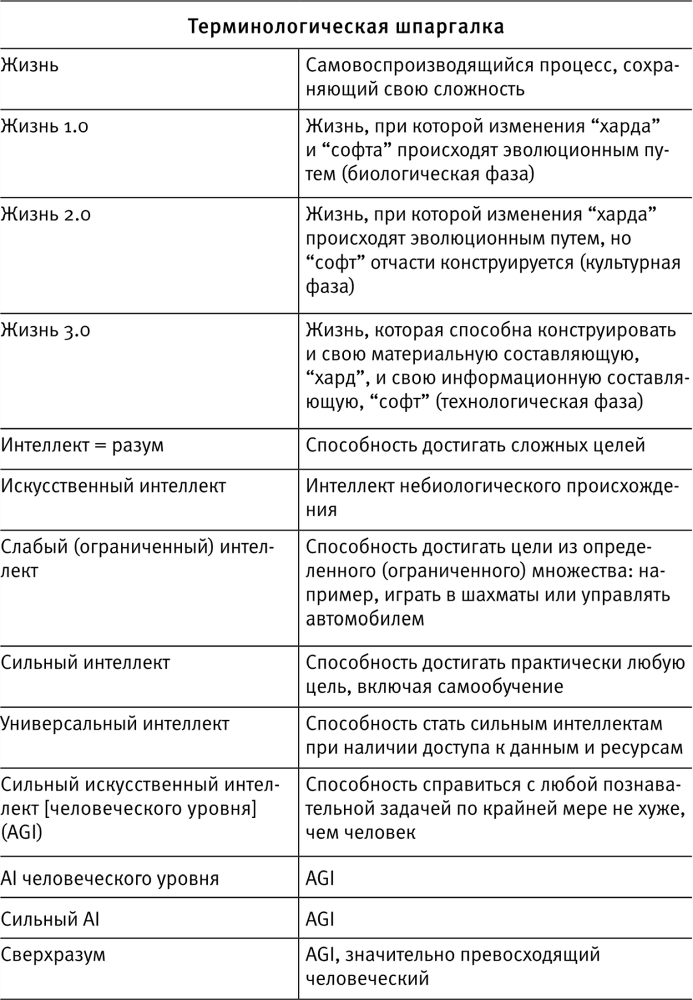
Многие недоразумения относительно искусственного интеллекта возникают из-за того, что люди используют приведенные в левой колонке слова для обозначения несхожих вещей. Здесь я привожу значения, в которых эти слова употребляются в этой книге. (Некоторые из этих определений будут введены и объяснены только в следующих главах книги.)
Кроме недоразумений, вызванных расхождениями в терминологии, я был свидетелем споров, возникавших по причине простых логических ошибок. Рассмотрим наиболее распространенные из них.
Хронологические мифы
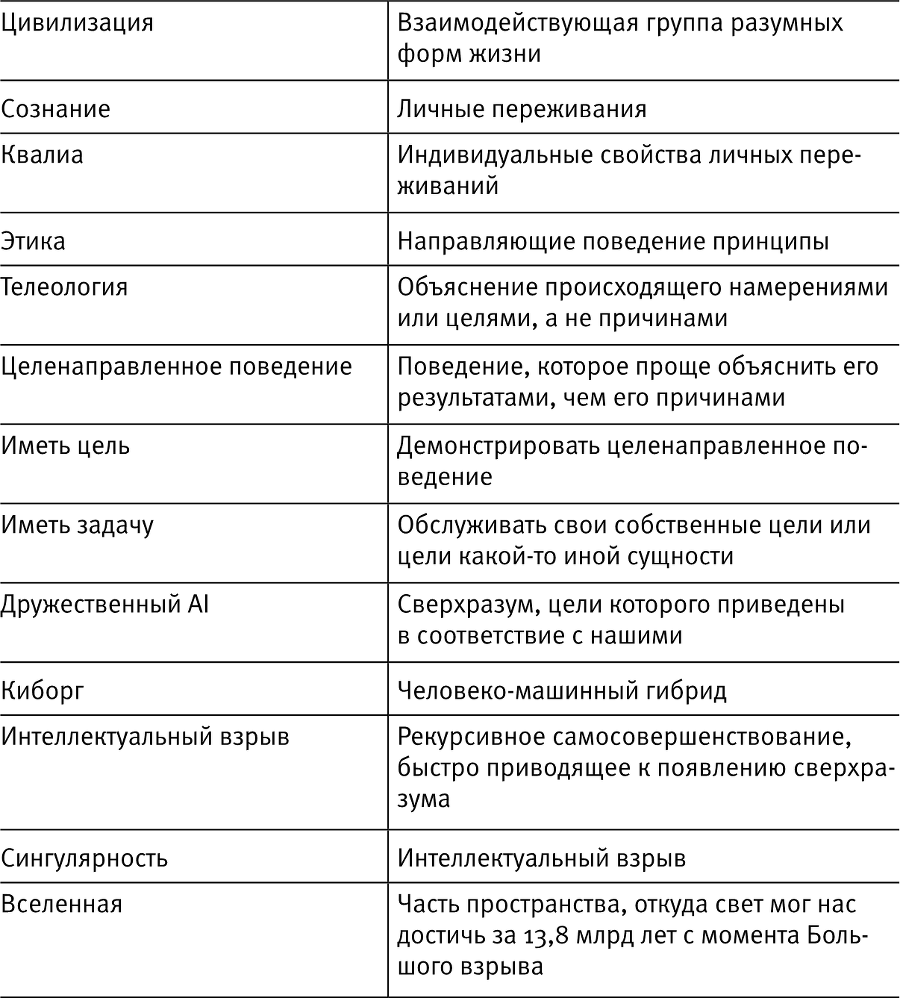
Первый проиллюстрирован на рис. 1.5: сколько времени понадобится, чтобы машинный интеллект мог принципиально превзойти человеческий разум? Самая большая ошибка здесь заключается в уверенности, что мы можем знать это с большой степенью точности.
Так, один популярный миф утверждает, что мы можем не сомневаться в появлении суперинтеллекта к концу этого столетия. В самом деле, история полна примеров чрезмерного оптимизма в отношении технологических достижений будущего. Где все эти давно обещанные нам термоядерные электростанции и летающие автомобили? С AI в прошлом тоже было связано немало чрезмерно завышенных ожиданий, в том числе этим грешили и некоторые основатели самой этой области: например, Джону Маккарти (автору термина “искусственный интеллект”), Марвину Мински, Натаниелю Рочестеру и Клоду Шеннону принадлежит следующий пассаж, содержащий оптимистический прогноз относительно того, что может быть проделано при помощи двух компьютеров каменного века за два месяца: “Наш проект заключается в том, чтобы 10 человек проводили на протяжении двух месяцев летом 1956 года исследование искусственного интеллекта в Дартмутском колледже … Будет сделана попытка научить машины использовать язык, формировать абстракции и общие понятия, решать некоторые типы задач, в настоящее время доступных только людям, и самосовершенствоваться. Мы полагаем, что в одном или нескольких из предложенных направлений может быть достигнут существенный прогресс, если тщательно отобранная группа ученых будет заниматься ими на протяжении лета”.

Рис. 1.5
Типичные мифы об искусственном интеллекте.
С другой стороны, у нас есть и анти-миф: мы можем не сомневаться в том, что суперинтеллект не появится до конца этого столетия. Исследователи предлагают широкий спектр оценок того, как далеко мы находимся от сверхчеловеческого AGI, но мы никак не можем с уверенностью утверждать, что вероятность получить его к концу века равна нулю, особенно если примем во внимание всю историю удручающе низкой точности предсказаний подобного рода техноскептиков. Вспомним, как Эрнест Резерфорд, по общему признанию величайший физик-ядерщик своего времени, уже в 1933 году – всего лишь за 24 года до открытия Лео Сцилардом ядерных цепных реакций – называл возможность получения ядерной энергии “лунным светом”, или как в 1956 году королевский астроном Ричард Вули называл разговоры о полетах в космос “полной мутью”. Крайнюю форму этот миф принимает в рассуждениях об искусственном интеллекте, который никогда не сможет стать сверхчеловеческим, потому что это физически невозможно. Но физики знают, что мозг состоит из кварков и электронов, упорядоченных так, что они могут работать как мощный компьютер, и что нет такого физического закона, который мог бы помешать нам создать еще более разумный комок кварков.
Было проведено несколько крупных исследований на экспертных фокус-группах среди специалистов по искусственному интеллекту, где им предлагалось оценить, сколько времени от текущего момента может пройти, пока вероятность создания искусственного интеллекта человеческого уровня достигнет 50 %, и все эти исследования оканчивались одним и тем же: мнения ведущих мировых исследователей по этому поводу расходятся, так что мы просто не знаем. Например, во время такого опроса на нашей конференции в Пуэрто-Рико медианный ответ соответствовал 2055 году, но некоторые предсказывали сотни лет или даже больше.
Еще один имеющий отношение к тому же вопросу миф заключается в том, что люди, переживающие по поводу искусственного интеллекта, ждут его появления уже в ближайшие годы. На самом же деле подавляющее большинство из тех, чье мнение в данном вопросе значимо и кто действительно беспокоится о негативных последствиях создания AI, не ждут его раньше, чем через несколько десятилетий. Но они говорят: коль скоро у нас нет 100 % гарантий, что такое не может случиться уже в этом столетии, стоит начать вести исследования вопросов AI-безопасности уже сейчас и быть готовыми к неожиданностям. Как мы увидим в этой книге, некоторые из вопросов безопасности настолько сложны, что на их решение могут уйти десятилетия, и есть смысл заняться ими сейчас, а не накануне той ночи, когда какие-то попивающие “Рэд Булл” программисты решат запустить AGI человеческого уровня.
Мифы несогласных
Еще одно недоразумение часто возникает по причине распространенного заблуждения, заключающегося в том, что только современные луддиты, не очень-то знакомые с темой, могут выражать какие-то опасения по поводу искусственного интеллекта и призывать к исследованию связанных с ним рисков. Когда Стюарт Рассел сказал об этом во время своего выступления на конференции в Пуэрто-Рико, аудитория откликнулась громким смехом. С этим заблуждением связано еще одно общее недоразумение: что поддержка таких исследований – дело якобы исключительно спорное. В действительности для их проведения в разумных масштабах достаточно скромных инвестиций, и для этого не надо считать риски высокими – надо просто понимать, что ими невозможно пренебречь. Так, исходя из невозможности пренебречь очень невысокой вероятностью, что ваш дом сгорит дотла, вы отчисляете небольшую часть своего дохода на страхование недвижимости.
Мой собственный анализ проблемы привел меня к убеждению, что именно из-за тенденциозного освещения в масс-медиа вопросы АI-безопасности кажутся значительно более спорными, чем на самом деле. В конце концов, страх – востребованный товар, и вырванные из контекста цитаты, если из них можно сделать вывод о неминуемо надвигающейся катастрофе, соберут больше кликов, чем уравновешенный и детальной отчет о проблеме. Поэтому два человека, знающие о позиции друг друга только по опубликованным цитатам, скорее всего решат, что поводов не согласиться с мнением оппонента у них гораздо больше, чем на самом деле. Например, техноскептик, чьи представления о взглядах Билла Гейтса основаны исключительно на сведениях из британского таблоида, наверняка подумает, что тот полагает появление суперинтеллекта неминуемым, – и конечно же будет неправ. Похожим образом некто, выступающий за создание дружественного AI, прочитав процитированное выше высказывание Эндрю Ына относительно перенаселения Марса, подумает, что того не заботят проблемы AI-безопасности, и тоже ошибется. Я точно знаю, что они его заботят, – но все дело в том, что из-за его особой оценки временных масштабов возникающих проблем он отдает приоритет более близким по времени проблемам.
Мифы о природе рисков
Прочитав в Daily Mail заголовок “Стивен Хокинг предостерегает, что восстание роботов может оказаться катастрофическим для человечества”, я закрыл глаза{2}. Я уже потерял счет таким статьям. Обычно они сопровождаются картинкой со злобным роботом, волокущим какое-нибудь оружие, и готовят нас к тому, что когда-нибудь роботы обретут сознание, преисполнятся злобой и поднимут восстание, которого нам следует опасаться. В определенном смысле такие статьи производят на меня сокрушительное впечатление, потому что в сжатой форме предлагают как раз тот самый сценарий, который никак не пугает моих коллег по исследованию AI. Этот сценарий содержит в себе сразу три глубочайших заблуждения, относящихся к трем разным понятиям: наше беспокойство должны вызывать сознание, злобность и вообще роботы.