Исследование двоичного поиска
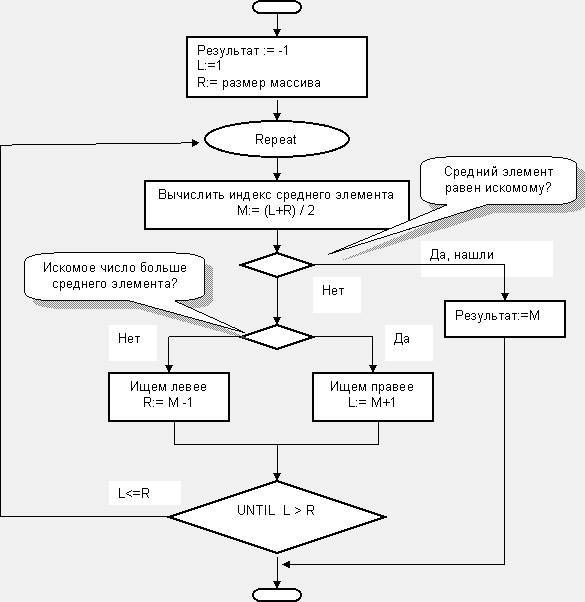
Частью этой программы будет функция двоичного поиска, алгоритм которой раскрыл зверолов. Но не худо привести и блок-схему этого чудесного изобретения. На блок-схеме (рис. 92), как и в программе, индексы элементов обозначены начальными буквами соответствующих английских слов: L – левый индекс (Left), R – правый индекс (Right), и M – средний индекс (Middle).
Рис.92 – Блок-схема алгоритма двоичного поиска
Функцию, работающую по этому алгоритму, я назвал FindBin (Find – «поиск», Binary – «двоичный»), она показана ниже. Полагаю, что приведенных в ней комментариев будет достаточно.
{ Функция двоичного поиска }
function FindBin (aNum: integer): integer;
var L, M, R : integer; { левый, правый и средний индексы }
begin
FindBin:= -1; { результат на случай неудачи }
L:= 1; R:= CSize; { начальные значения индексов }
repeat
M:= (L+R) div 2; { индекс среднего элемента }
if aNum= ArrSort[M] then begin
FindBin:= M; { нашли ! }
Break; { успешный выход из цикла }
end;
if aNum > ArrSort[M] { где искать дальше? }
then L:= M+1 { ищем правее }
else R:= M–1; { ищем левее }
until L > R; { выход при неудачном поиске }
end;
Теперь мы готовы создать исследовательскую программу, которая будет сравнивать два способа поиска.
Поступим так. Объявим два массива по 1000 чисел в каждом. Заполним их случайным образом и один из них отсортируем. Затем сделаем ряд экспериментов, каждый из которых состоит в следующем. Выбрав наугад одно из чисел массива, программа вызовет по очереди две функции: сначала последовательно найдет число в несортированном массиве, а затем двоичным поиском – в сортированном. Поскольку искомое число выбрано из массива, то поиск всегда будет успешным. Затраченные на поиск шаги подсчитаем, и результаты запишем в текстовый файл. После каждого такого эксперимента программа будет ожидать команды пользователя: приняв число ноль, она завершится, а иначе повторит эксперимент.
Подсчет шагов будем вести в глобальной переменной Steps (шаги). Перед вызовом функций поиска она обнуляется, а внутри функций наращивается (эти операторы внутри функций выделены курсивом). Вот и все, полюбуйтесь на эту «экспериментальную установку», введите в компьютер и запустите на выполнение.
{ P_42_1 – Исследование методов поиска }
const CSize = 1000; { размер массива }
{ объявление типа для массива }
Type TNumbers = array [1..CSize] of integer;
Var ArrRand : TNumbers; { несортированный массив }
ArrSort : TNumbers; { сортированный массив }
Steps : integer; { для подсчета числа шагов поиска }
{ Процедура "пузырьковой" сортировки чисел в порядке возрастания }
procedure BubbleSort(var arg: TNumbers);
var i, j, t: Integer;
begin
for i:= 1 to CSize-1 do { внешний цикл }
for j:= 1 to CSize-i do { внутренний цикл }
if arg[j] > arg[j+1] then begin { обмен местами }
t:= arg[j]; arg[j]:= arg[j+1]; arg[j+1]:= t;
end;
end;
{ Функция последовательного поиска (Find Sequence) }
function FindSeq (aNum: integer): integer;
var i: integer;
begin
FindSeq:= -1; { если не найдем, результат будет -1 }
for i:=1 to CSize do begin
Steps:= Steps+1; { подсчет шагов поиска }
if aNum= ArrRand[i] then begin
FindSeq:= i; { нашли, возвращаем позицию }
Break; { выход из цикла }
end;
end;
end;
{ Функция двоичного поиска (Find Binary) }
function FindBin (aNum: integer): integer;
var L, M, R : integer;
begin
FindBin:= -1;
L:= 1; R:= CSize;
repeat
Steps:= Steps+1; { подсчет шагов поиска }
M:= (L+R) div 2;
if aNum= ArrSort[M] then begin
FindBin:= M; { нашли ! }
Break; { выход из цикла }
end;
if aNum > ArrSort[M]
then L:= M+1
else R:= M-1;
until L > R;
end;
{--- Главная программа ---}
Var i, n, p : integer; { вспомогательные переменные }
F: text; { файл результатов }
begin
Assign(F,'P_42_1.OUT'); Rewrite(F);
{ Заполняем массив случайными числами }
for i:=1 to CSize do ArrRand[i]:=1+Random(10000);
ArrSort:= ArrRand; { копируем один массив в другой }
BubbleSort(ArrSort); { сортируем второй массив }
repeat { цикл с экспериментами }
i:= 1+ Random(CSize); { индекс в пределах массива }
n:= ArrRand[i]; { случайное число из массива }
Writeln(F,'Искомое число= ', n);
Steps:=0; { обнуляем счетчик шагов поиска }
p:= FindSeq(n); { последовательный поиск }
Writeln(F,'Последовательный: ', 'Позиция= ',
p:3, ' Шагов= ', Steps);
Steps:=0; { обнуляем счетчик шагов поиска }
p:= FindBin(n); { двоичный поиск }
Writeln(F,'Двоичный поиск: ', 'Позиция= ',
p:3, ' Шагов= ', Steps);
Write('Введите 0 для выхода из цикла '); Readln(n);
until n=0;
Close(F);
end.
Вот результаты трех экспериментов.
Искомое число= 5026
Последовательный: Позиция= 544 Шагов= 544
Двоичный поиск: Позиция= 518 Шагов= 10
Искомое число= 8528
Последовательный: Позиция= 828 Шагов= 828
Двоичный поиск: Позиция= 854 Шагов= 10
Искомое число= 7397
Последовательный: Позиция= 100 Шагов= 100
Двоичный поиск: Позиция= 748 Шагов= 9
Я не поленился проделать 20 опытов, результаты которых занес в табл. 7. Среднее число шагов поиска для каждого из методов посчитано мною на калькуляторе и внесено в последнюю строку таблицы.
Табл. 7- Результаты исследования алгоритмов поиска
Экспе-римент
Искомое число
Количество шагов поиска
Последовательный поиск
Двоичный поиск
1
5026
544
10
2
8528
828
10
3
7397
100
9
4
2061
52
9
5
8227
634
9
6
9043
177
10
7
4257
10
10
8
3397
704
5
9
4021
887
10
10
8715
815
9
11
6811
53
9
12
5959
141
10
13
928
859
7
14
3295
26
10
15
9534
935
10
16
1618
8
6
17
1066
105
8
18