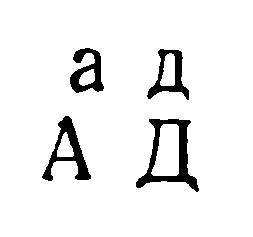+ 628318530 + 01
- 141421356
+ 01 + 000000000
+ 00 + 000000000 + 00
«МАГНИТНЫЕ ЧЕРНИЛА»
Нельзя ли как-то упростить все эти процедуры? Допустим, нам нужен перевод текста с помощью машины. Кодирование букв числами, набивка этих чисел на перфокарты, затем эти же процедуры в обратном порядке — все это, по существу, лишняя работа. Вот если бы было так: на «вход» машины мы кладем книгу на неизвестном языке, а через несколько минут «на выходе» получаем эту книгу, но уже переведенную на русский или какой-либо другой известный нам язык.
Если будет создан язык-посредник, то машинный перевод с любого и на любой язык мира возможен. Однако все процедуры с кодированием, перфокартами и т. п. остаются и занимают, конечно, немало времени.
Если бы машина умела сама читать! Тогда задача была бы гораздо проще... Возможно ли обучить машину чтению?
Еще в начале нынешнего века был дан ответ: «да, возможно». Изобретатель д’Альба еще в 1904 году построил «Оптофон» — машину для чтения печатного текста. В наши дни читающие устройства, достигшие, конечно, гораздо большего совершенства, чем «Оптофон», начинают выполнять роль «глаза» и для электронных вычислительных машин.
Каждая буква печатного текста занимает определенное пространство. Это пространство можно разбить на маленькие прямоугольники. Они могут быть либо черными (если на них есть типографская краска буквы), либо белыми. Фотоэлемент может теперь произвести кодирование буквы. Если квадрат черный, тока в фотоэлементе не будет. Если белый, ток по-прежнему сохранится.
«Черное — белое», «да —- нет», «есть ток — нет тока»... «нуль — единица». В который раз мы встречаемся с универсальной арифметикой электронных вычислительных машин! Просматривая все квадратики, из которых состоит буква, фотоэлемент превращает изображение буквы в набор нулей и единиц. Буква теперь «понятна» машине — ведь она стала двоичным числом!
Вот как происходит считывание буквы по методу телевизионной развертки: фотоэлемент просматривает букву сверху вниз, превращая ее в последовательность электрических сигналов.
Каждая буква — двоичное число. Допустим, «а» — это число 10001010111, «б» —01110011000, и т. д. Если мы пользуемся одним и тем же типографским шрифтом, то наши числа-буквы будут однозначны.
Ну, а если взять другой шрифт? Если набрать буквы «а» не обычным шрифтом, а курсивом? Очертания буквы изменятся. Значит, изменится и число. Как же быть тогда? Очевидно, нужно вложить в «память» машины сведения о том, что не только число 10001010111, но и число 11001010111 («а» курсивное) также является буквой «а».
Типографских вариантов букв не так уж много. Печатные буквы стандартны, в них нет никаких «вариантов почерка». Но как быть с рукописными текстами? Ведь в них сотни и тысячи различных по начертанию букв «а», «б» и др. И тем не менее применять машины для чтения рукописных букв необходимо. И прежде всего, в банковском деле. В 1960 году в обращении находилось более 50 миллиардов банковских чеков. В годовом обороте каждый документ обрабатывается примерно 10 раз. Вот и посчитайте, сколько времени нужно затратить на обработку чеков!
В настоящее время машины овладели техникой чтения банковских документов. Ежегодно они обрабатывают миллионы чеков. Успехи машины объясняются тем, что читать ей нужно всего лишь 10 различных знаков-цифр. К тому же они пишутся на чеках разборчиво — как-никак денежный документ!
Помогают и специальные «магнитные чернила». Они сделаны из смеси красителя и тонко помолотого магнитного порошка. Запись такими «чернилами» может читаться машиной без помощи фотоэлемента.
Вначале документ проходит под намагничивающей головкой. Потом — под несколькими «читающими головками», расположенными подобно головкам обычного магнитофона. Знаками, написанными «магнитными чернилами», возбуждаются электрические импульсы. Величина импульсов зависит от формы знака. Сочетание коротких и сильных импульсов дает двоичное число, и автомат может читать чек.
Благодаря таким «магнитным чернилам» в одном из американских банков машина обработала за год 6 миллионов чеков. Процент ошибок был очень мал — 0,75. А при ручной обработке процент ошибок в четыре раза больше, не говоря уже о том, что машина читает чеки со скоростью 100 цифр в секунду, явно недоступной человеку.
ОБРАЗЫ И БУКВЫ
Но и «магнитные чернила» не помогут, если писать неразборчивым почерком. Как научить машину читать любой рукописный текст? Эта проблема является частью более общей задачи — машинного распознавания образов.
Все течет, все изменяется, говорил великий греческий философ Гераклит. В самом деле, действительность, окружающая нас, вечно меняется. Нельзя войти дважды в одну и ту же реку, нельзя увидеть дважды одну и ту же вещь: что-то в ней меняется каждую секунду. Повторяемости впечатлений не существует. И тем не менее мы считаем реку рекой, вещь вещью.
Почему?
Да потому, что наш мозг, и не только мозг, но и глаз, совершают постоянную работу по абстрагированию, обобщению потока впечатлений из внешнего мира.
Органы чувств человека получают такое количество информаций, что мозг не может обработать ее полностью. Он вынужден перерабатывать первичные восприятия в понятия и образы. Мы видим сотни самых различных собак: дворняжек, сеттеров, бульдогов, гаке; рыжих, пегих, белых, бурых, маленьких, коротконогих, гигантских, голенастых. И все же, несмотря на такое множество пород, мастей и размеров, мы всегда отличим собаку от кошки.
Благодаря образному зрению мы можем узнавать предметы, которых раньше никогда не видели, но которые относятся к уже известным нам образам. Распознавание образов позволяет человеку не только экономить свою память, но и использовать предыдущий опыт. Если бы человек не умел распознавать образы, он мог бы читать только почерки, которые видел раньше. Чтобы понимать незнакомые почерки, их нужно было бы специально изучать. И знание других почерков никак не помогало бы осваивать новый.
Человек распознает образы на основании своего опыта и, быть может, переданных ему по наследству навыков. А как научить образному зрению машину?
Задача была бы не слишком трудной, если бы мы могли описать все возможные образы. Например, все варианты буквы «а» в ее различных начертаниях. Но вряд ли кто сумеет сделать это. Слишком много вариантов всех возможных почерков. К тому же нам достаточно увидеть несколько букв «а», чтобы в дальнейшем безошибочно «угадывать» эту букву в любом шрифте и почерке. Как же это делается?
«Я бы в ноги поклонился тому физиологу, который сможет математически четко объяснить, как человек безошибочно отличает собаку от кошки», — говорил один из крупных советских кибернетиков. И за шутливой фразой скрыто серьезное содержание. Вся трудность распознавания образов заключается в том, чтобы найти содержательные признаки, с помощью которых человек отличает букву «а» от буквы «б», один образ от другого. Вот перед нами четыре буквы:
К какому классу отнести их? Ведь можно разделить эти буквы на строчные и заглавные: одна группа — «а», «д», другая — «А», «Д». Но можно и на буквы «а» и буквы «д» («а», «А» и «д», «Д»). В первом случае мы произвели деление по шрифту, геометрическое. Во втором — по смыслу, алфавитное.
Построить систему признаков, по которым можно отличить негра от европейца, нетрудно. Достаточно указать цвет кожи. Но попробуйте назвать признаки, по которым можно было бы найти вашего приятеля в толпе других ребят!