Таблица 2.4. Значения поля e_machine заголовка ELF-файла
| Значение | Аппаратная платформа |
ЕМ_М32
| AT&T WE 32100 |
ЕМ_SPARC
| Sun SPARC |
ЕМ_386
| Intel 80386 |
ЕМ_68K
| Motorola 68000 |
EM_88K
| Motorola 88000 |
ЕМ_486
| Intel 80486 |
ЕМ_860
| Intel i860 |
ЕМ_MIPS
| MIPS RS3000 Big-Endian |
EM_MIPS_RS3_LE
| MIPS RS3000 Little-Endian |
EM_RS6000
| RS6000 |
EM_PA_RISC
| PA-RISC |
EM_nCUBE
| nCUBE |
EM_VPP500
| Fujitsu VPP500 |
EM_SPARC32PLUS
| Sun SPARC 32+ |
Информация, содержащаяся в таблице заголовков программы, указывает ядру, как создать образ процесса из сегментов. Большинство сегментов копируются (отображаются) в память и представляют собой соответствующие сегменты процесса при его выполнении, например, сегменты кода или данных.
Каждый заголовок сегмента программы описывает один сегмент и содержит следующую информацию:
□ Тип сегмента и действия операционной системы с данным сегментом
□ Расположение сегмента в файле
□ Стартовый адрес сегмента в виртуальной памяти процесса
□ Размер сегмента в файле
□ Размер сегмента в памяти
□ Флаги доступа к сегменту (запись, чтение, выполнение)
Часть сегментов имеет тип LOAD, предписывающий ядру при запуске программы на выполнение создать соответствующие этим сегментам структуры данных, называемые областями, определяющие непрерывные участки виртуальной памяти процесса и связанные с ними атрибуты. Сегмент, расположение которого в ELF-файле указано в соответствующем заголовке программы, будет отображен в созданную область, виртуальный адрес начала которой также указан в заголовке программы. К сегментам такого типа относятся, например, сегменты, содержащие инструкции программы (код) и ее данные. Если размер сегмента меньше размера области, неиспользованное пространство может быть заполнено нулями. Такой механизм, в частности используется при создании неинициализированных данных процесса (BSS). Подробнее об областях мы поговорим в главе 3.
В сегменте типа INTERP хранится программный интерпретатор. Данный тип сегмента используется для программ, которым необходимо динамическое связывание. Суть динамического связывания заключается в том, что отдельные компоненты исполняемого файла (разделяемые объектные файлы) подключаются не на этапе компиляции, а на этапе запуска программы на выполнение. Имя файла, являющегося динамическим редактором связей, хранится в данном сегменте. В процессе запуска программы на выполнение ядро создает образ процесса, используя указанный редактор связей. Таким образом, первоначально в память загружается не исходная программа, а динамический редактор связей. На следующем этапе динамический редактор связей совместно с ядром UNIX создают полный образ исполняемого файла. Динамический редактор загружает необходимые разделяемые объектные файлы, имена которых хранятся в отдельных сегментах исходного исполняемого файла, и производит требуемое размещение и связывание. В заключение управление передается исходной программе.
Наконец, завершает файл таблица заголовков разделов или секций (section). Разделы (секций) определяют разделы файла, используемые для связывания с другими модулями в процессе компиляции или при динамическом связывании. Соответственно, заголовки содержат всю необходимую информацию для описания этих разделов. Как правило разделы содержат более детальную информацию о сегментах. Так, например, сегмент кода может состоять из нескольких разделов, таких как хэш-таблица для хранения индексов используемых в программе символов, раздел инициализационного кода программы, таблица связывания, используемая динамическим редактором, а также раздел, содержащий собственно инструкции программы.
Мы еще вернемся к формату ELF в главе 3 при обсуждении организации виртуальной памяти процесса, а пока перейдем к следующему распространенному формату — COFF.
Формат COFF
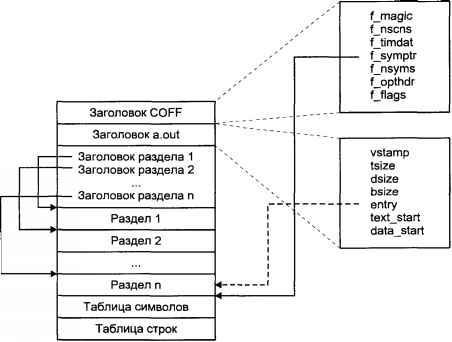
На рис. 2.5 приведена структура исполняемого файла формата COFF. Исполняемый файл содержит два основных заголовка — заголовок COFF и стандартный заголовок системы UNIX — a.out. Далее следуют заголовки разделов и сами разделы файла, в которых хранятся инструкции и данные программы. Наконец, в файле также хранится символьная информация, необходимая для отладки.
Рис. 2.5. Структура исполняемого файла в формате COFF
В файле находятся только инициализированные данные. Поскольку неинициализированные данные всегда заполняются нулями при загрузке программы на выполнение, для них необходимо хранить только размер и расположение в памяти.
Символьная информация состоит из таблицы символов (symbol table) и таблицы строк (string table). В первой таблице хранятся символы, их адреса и типы. Например, мы можем определить, что символ
locptr
является указателем и его виртуальный адрес равен 0x7feh0. Далее, используя этот адрес, мы можем выяснить значение символа для выполняющегося процесса. Записи таблицы символов имеют фиксированный размер. Если длина символа превышает восемь знаков, его имя хранится во второй таблице — таблице строк. Обычно обе эти таблицы присутствуют в объектных и исполняемых файлах, если они явно не удалены, например, командой
strip(1).
Как и в случае ELF-файла, заголовок содержит общую информацию, позволяющую определить местоположение остальных компонентов (табл. 2.5).
Таблица 2.5. Поля заголовка COFF-файла
| Поле | Описание |
f_magic
| Аппаратная платформа, для которой создан файл |
f_nscns
| Количество разделов в файле |
f_timdat
| Время и дата создания файла |
f_symptr
| Расположение таблицы символов в файле |
f_nsyms
| Количество записей в таблице символов |
f_opthdr
| Размер заголовка |
f_flags
| Флаги, указывающие на тип файла, присутствие символьной информации и т.д. |