В этих ответах рассчитывается также индекс информационного благоприятствования (ИИБ). Он учитывает массу факторов, связанных с упоминанием объекта: скажем, его роль в сообщении (уникален или перечислен в списке из десяти других), тональность оценки (позитив, негатив или нейтральность) и т. п. Формула расчета ИИБ сложна, как сложна и технология оценок, классификации подобных объектов с многочисленными атрибутами и – очень важно! – связями. Технология, используемая в системе, была разработана с участием известного математика, специалиста по классификации и статистическому анализу Юрия Благовещенского.
Именно благодаря этой технологии – надо подчеркнуть, что она не сводится к алгоритмам, заложенным в систему; выбор параметров классификации, методика их присвоения объектам, лингвистический анализ – все это тоже в конечном счете элементы технологии текст-майнинга – появляется возможность очень быстро получать ответы на сложные запросы к базе.
«Прочее», или В разведку
Для демонстрационного сеанса я попросил Катю поработать с давно знакомым «объектом», часто упоминаемым и на наших страницах – Российской академией наук.
Первым шагом был простой запрос списка публикаций, упоминающих РАН, с начала этого года (рис. 1). Их оказалось около пяти тысяч – включая и телесюжеты, которые можно было немедленно просмотреть. После этого мы заказали график динамики публикаций за тот же период, с разбивкой по неделям (рис. 2).
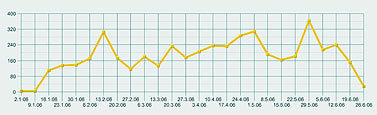
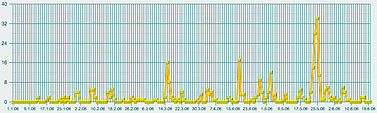
Полученная картинка выглядела не очень выразительно. Пики и спады были выражены нечетко, ясного представления о динамике общественного внимания к делам Академии они не давали. Вот тут мы и воспользовались одной из более сложных черт системы – запросили график числа публикаций, в которых Академия фигурировала в качестве главного объекта. Полученный по такому запросу рис. 3 был заметно более информативным. Как нетрудно заметить, он демонстрирует весьма четкие узкие пики, явно указывающие на серьезные события. Исследовать их все возможности не было, но щелкнув мышкой по самому позднему (он же самый высокий), мы взглянули на несколько появившихся на экране текстов, и сразу получили объяснение этому всплеску публикаций – в этот период прошли выборы новых академиков. С этим, как явствовало из тех же публикаций, была связана любопытная интрига с попыткой выдвижения в академики крупных бизнесменов и чиновников, чуть не приведшая к большому скандалу (Сергей Степашин, например, вежливо, но твердо отказался баллотироваться).
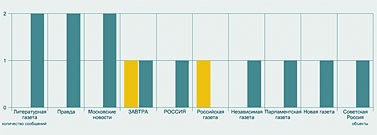
Следующий запрос – по каким рубрикам распределены упоминания Академии. И вот здесь нас поджидала маленькая сенсация. Полученную диаграмму вы видите на рис. 4. Оказывается, Академия наук чаще всего упоминается в наших СМИ в неведомых рубриках с собирательным названием «Прочее»! Там она фигурирует вдвое чаще, чем во второй по частоте категории – «Наука и образование», следующий по частоте контекст – «Власть», а процент упоминаний Академии как главного объекта статей по высоким технологиям находится уже где-то на уровне случайных колебаний.
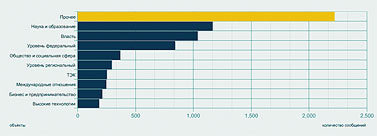
Катю Солнцеву результат удивил – никогда еще запрос ни по одному значимому объекту не давал такой статистики. Получается, что СМИ чаще всего пишут об Академии по каким-то нечетким, малозначительным поводам – и, что хуже всего, никак не связанным с ее основными миссиями. Разумеется, полученный результат надо еще уточнять и более детально анализировать. Но сигнал, тем не менее, весьма отчетливый: общество не очень понимает, чем занимается Академия, и далеко не всегда связывает ее деятельность с вопросами науки и образования.
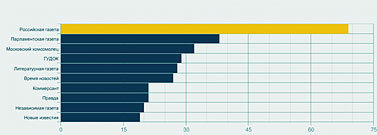
Следующий запрос – расклад по СМИ, упоминающим Академию (рис. 5). На первом месте – официоз (правительственная «Российская газета», «Парламентская газета»). Ведущие деловые издания пишут об Академии очень мало – скажем, «Ведомости» вообще не попали в список. Тест на позитив-негатив по тем же центральным газетам дал заметный перекос в сторону негатива (рис. 6) – но это вряд ли показательно, так как общее число таких сообщений очень мало – основная масса упоминаний оказалась просто нейтральной.
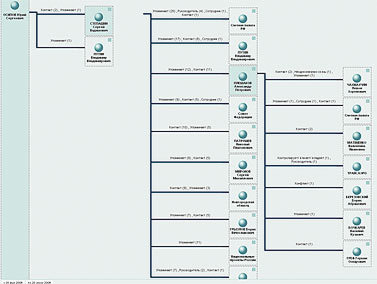
Ну а дальше мы попытались применить к собранной по академии статистике запросы как раз «разведывательного» характера. А именно, выбрав в качестве основного объекта Юрия Осипова [Вот пишу и думаю – а ведь и этот текст попадет в ту же самую базу, и тоже каким-то образом изменит статистику упоминаний и самой Академии, и ее президента…], Президента РАН, провели поиск по его «связям» с другими объектами – выстраивая при этом цепочки из двух промежуточных звеньев. Результат показан на рис. 7.
Очевидная интерпретация в данном случае невозможна – но характер получаемой информации ясен. Вряд ли более тщательный анализ именно этих цепочек раскроет какие-нибудь страшные тайны Академии наук. Не исключено, впрочем, что персонаж шпионских романов Ле Карре немедленно засел бы за просмотр всех документов, по которым выстроены отраженные на схеме связи. Мы же с вами можем просто обратить внимание на крайнюю узость круга людей, общение с которыми Президента Академии замечают СМИ.
Если бы речь шла о рыночной конкуренции, можно было бы использовать и другие типы запросов по связям: поиск совместных упоминаний, скажем, конкурента и его клиентов в конфликтном контексте, объявления о проектах и результатах их реализации, оценку «уровня бесконфликтности», в том числе в связи с госорганами, и т. д. В случае Академии все это неинтересно и неприменимо – хотя бы потому, что конкурентов у РАН нет.
Вот так сработал текст-майнинг на этом необычном (в «Медиалогии» не помнят, чтобы научные учреждения интересовались своим обликом в СМИ или динамикой репутации) запросе.
Предупреждая саркастические письма прожженных наших читателей, сообщаю – да, я в курсе, что за скромные тысячи рублей можно купить у добрых людей базы данных банковских проводок, таможенных операций по любой компании страны и другие исчерпывающие, казалось бы, «разведданные». По этому поводу можно сделать два комментария. Во-первых, использование нелегальных источников информации дает, мягко говоря, не только преимущества. Во-вторых – персонализированных репутационных исследований нужной вам компании, сделанных по результатам вот такого интеллектуального мониторинга СМИ, у пиратов заведомо нет.
Впрочем, обсуждать, что дает и чего не дает текст-майнинг «на самом деле» здесь бессмысленно. В России пара сотен компаний, общественных и госорганизаций использует эти технологии – это факт. Для чего это им нужно, насколько им это полезно – вопрос слишком тонкий, ибо одно из главных условий, которые должны быть обеспечены пользователям таких систем – секретность содержания их запросов.
Краткое философское послесловие
О текст-майнинге приятнее всего рассуждать в абстрактных терминах и в будущем времени. Например, ясно, что здесь огромное поле для новых технологий поиска, взрывного роста которых мы все еще ждем. Ясно также, что развитие таких систем будет продолжаться, но потребует серьезных инвестиций (вышеупомянутая Factiva принадлежит сразу двум мощнейшим новостным агентствам, Reuters и Dow Jones; «Медиалогия» – проект нашего ИТ-гиганта IBS). Любопытно было бы и разобраться подробнее, что в таком контексте вкладывается (формально) в такие понятия как «факт», «достоверность».
Но при знакомстве с используемой на практике системой текст-майнинга лично мне интереснее всего было убедиться, что никакие иллюзии насчет точности и качества «машинного» анализа текстов в систему не закладываются. Без сотни аналитиков ничего работать не будет – но без всей этой сложной программной лингвистическо-статистической кухни нужны были бы не сотни, а тысячи, а интервалы между запросами и ответами исчислялись бы не минутами, а неделями. Именно это, по-видимому, и обеспечивает сегодня существующую узкую рыночную нишу для текст-майнинга. Но она несомненно будет расти. Все больше говорят о потенциале «тегового» индексирования информации, и оно может радикально удешевить такие разработки. Впрочем, «персональной разведслужбы» пока не видно даже на горизонте.