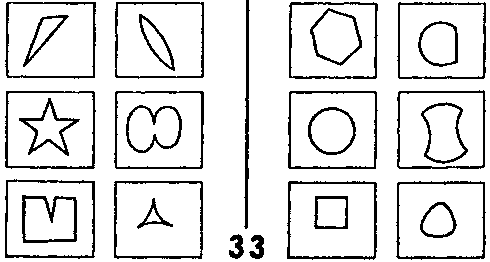
Рис. 124 Задачи Бонгарда.
Переход и пробность
Понятие перехода между похожими предметами родственно понятию восприятия одного предмета как вариации другого. Мы уже видели прекрасный пример этого — «круг с тремя выемками», который на самом деле вовсе не круг! Наши понятия должны быть до определенной степени гибкими. Ничто не должно оставаться совершенно неизменным. С другой стороны, они также не должны быть настолько бесформенными, что в них пропадет всякое значение. Все дело в том, чтобы знать, когда одно понятие может перейти в другое.
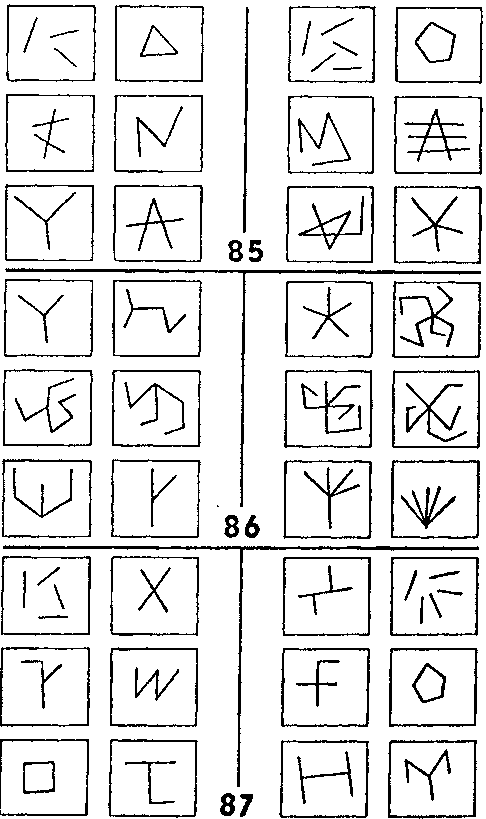
Такой переход лежит в основе решений задач Бонгарда ##85 — 87 (рис. 125). ЗБ #85 довольно проста. Предположим, что наша программа в процессе предварительной обработки данных узнает некий «отрезок». После этого ей легко посчитать отрезки и найти различие между классом I и классом II в ЗБ #85.
Теперь программа переходит к задаче #86. Ее основная методика состоит в том, чтобы опробовать все недавние идеи, оказавшиеся удачными. В реальном мире повторение сработавших ранее приемов часто увенчивается успехом, и Бонгард в своих задачах не стремится перехитрить этот тип эвристики—к счастью, он даже поощряет его. Таким образом, мы переходим к ЗБ #86, имея на вооружении две идеи («считать» и «отрезок»), слитые в одну: «считать отрезки». Но оказывается, что в ЗБ #86 вместо отрезков нужно считать последовательности линий. Последовательность линий здесь означает сцепление (одного или более) отрезков. Программа может догадаться об этом, например, благодаря тому, что ей известны оба понятия, «отрезок прямой» и «последовательность прямых», и что они расположены близко друг от друга в сети понятий. Другим, способом было бы изобретение понятия «последовательность прямых» — задача, мягко выражаясь, не из простых.
Далее следует ЗБ #87, в которой понятие «отрезок» обыгрывается по-иному. Когда один отрезок становится тремя? (См. рамку II-А.) Программа должна быть достаточно гибкой, чтобы переходить взад и вперед между различными описаниями данного фрагмента рисунка. Разумно сохранять в памяти старые описания, вместо того, чтобы их забывать и затем составлять снова, поскольку нет гарантии того, что новое описание окажется лучше прежнего. Таким образом, вместе с каждым старым описанием программа должна запоминать его сильные и слабые стороны. (Не правда ли, это начинает звучать довольно сложно?)
Рис. 125. Задачи Бонгарда ##85 — 87 (Из книги Бонгарда «Проблема узнавания»).
Мета-описания
Теперь мы подошли к другой жизненно важной части процесса узнавания; она имеет дело с уровнями абстракции и мета-описаниями. Для примера давайте вернемся к ЗБ #91 (рис. 121). Какой эталон можно здесь построить? С таким количеством вариантов трудно знать, откуда начинать. Но это уже само по себе является подсказкой! Это говорит нам, что различие между классами, скорее всего, существует на уровне, высшем чем уровень геометрических описаний. Это наблюдение подсказывает программе, что она может попытаться рассмотреть описания описаний — то есть мета-описания. Может быть, на этом втором уровне нам удастся обнаружить какие-либо общие черты, и, если повезет, найти достаточно сходства для того, чтобы создать эталон для мета-описаний. Таким образом, мы начинаем работу без эталона и создаем описания нескольких рамок; после того, как они закончены, мы описываем сами эти описания. Какие гнезда будут у нашего эталона для мета-описаний? Может быть, следующие:
использованные понятия: —
повторяющиеся понятия: —
названия гнезд: —
использованные фильтры: —
Существует множество других гнезд, которые могут быть использованы в мета-описаниях; это просто пример. Предположим теперь, что мы описали рамку I-Д в ЗБ #91. Ее «безэталонное» описание может выглядеть так:
горизонтальный отрезок.
вертикальный отрезок, находящийся на горизонтальном отрезке.
вертикальный отрезок, находящийся на горизонтальном отрезке.
вертикальный отрезок, находящийся на горизонтальном отрезке.
Разумеется, множество сведений было отброшено: то, что три вертикальных отрезка одинаковой длины, отстоят друг от друга на одно и то же расстояние и т. п. Но возможно и подобное описание. Мета-описание может выглядеть так:
использованные понятия: вертикальный-горизонтальный, отрезок, находящийся на
повторяющиеся понятия: 3 копии описания «вертикальный отрезок, находящийся на горизонтальном отрезке».
названия гнезд: —
использованные фильтры: —
Не все гнезда мета-описания должны быть заполнены: на этом уровне тоже возможно отбрасывание информации, как и на уровне «простого описания». Если бы мы теперь захотели составить описание и мета-описание любой другой рамки класса I, то гнездо «повторяющиеся описания» каждый раз содержало бы фразу «три копии ...» Детектор сходства заметил бы это и выбрал бы «тройничность» в качестве общей абстрактной черты рамок класса I. Таким же образом, путем мета-описаний может быть установлено, что «четверичность» — отличительная черта класса II.
Важность гибкости
Вы можете возразить, что использование мета-описаний в данном случае напоминает стрельбу по мухам из пушки, поскольку тройничность и четверичность могли быть найдены уже на первом уровне, если бы мы построили наше описание немного иначе. Это верно, но для нас важно иметь возможность решать эти задачи различными путями. Программа должна быть очень гибкой; она не должна быть обречена на провал, если ее «занесет» не туда. Я хотел проиллюстрировать общий принцип: когда построение эталона затруднено, потому что препроцессор запутывается среди различных деталей, это показывает, что здесь задействованы понятия на высших уровнях, о которых препроцессор ничего не знает.
Фокусирование и фильтрование
Теперь давайте рассмотрим другой вопрос: каким образом можно отбрасывать информацию. Ответ на этот вопрос включает два родственных понятия, которые я называю «фокусированием» и «фильтрованием». Фокусирование означает составление описания так, что оно сосредотачивается на каком-то одном районе картинки и «сознательно» оставляет без внимания все остальные. Фильтрование означает составление описания так, что оно видит содержимое картинки под каким-то определенным углом, и сознательно игнорирует все другие аспекты.
Таким образом, они дополняют друг друга: фокусирование имеет дело с объектами (грубо говоря, с существительными), а фильтрование — с понятиями (грубо говоря, с прилагательными).
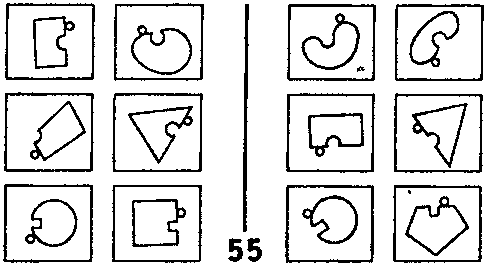
Рис. 126. Задача Бонгарда #55 (Из книги Бонгарда «Проблема узнавания»).
Для примера фокусирования рассмотрим ЗБ #55 (рис. 126). Здесь мы сосредотачиваемся на выемке и маленьком круге около нее, и оставляем без внимания все остальное. ЗБ #22 — это пример фильтрования. Мы отбрасываем все понятия, кроме размера. Для решения ЗБ #58 (рис. 128) требуется комбинация фокусирования и фильтрования.
Одним из важных способов получения идей для фокусирования и фильтрования является другой тип «фокусирования»: детальный анализ какой-либо особенно простой рамки — скажем, рамки с наименьшим количеством предметов. Очень полезным может оказаться сравнение между гобой простейших рамок обоих классов.
Но каким образом программа определяет, какие рамки самые простые, до того, как она производит их описание? Одним из способов определения простоты является поиск рамки с наименьшим количеством черт, найденных препроцессором. Это может быть сделано на ранних стадиях работы, поскольку для этого не нужен готовый эталон; на самом деле, это может быть использовано как поиск черт для включения в эталон. ЗБ #61 (рис. 129) — пример случая, когда такая техника дает плоды очень быстро.