Этот процесс создает две новые двойные цепочки ДНК, каждая из которых идентична первоначальной. Если мы будем пользоваться этой идеей в нашем решении, нам потребуется набор белков, закодированных в самой ДНК, которые смогут выполнить эти два шага.
Считается, что в клетке эти шаги осуществляются одновременно, это происходит координированно и требует присутствия трех основных энзимов эндонуклеазы ДНК, полимеразы ДНК и лигазы ДНК. Первый — «открывающий энзим», разделяющий цепочки, словно две части застежки «молнии». Потом вступают в действие два остальных энзима. Полимераза ДНК — это энзим копирования и передвижения; он медленно передвигается вдоль коротких цепочек ДНК, воспроизводя их дополнения методом, похожим на типогенетический. Для этого он пользуется материалом-сырцом — а именно, нуклеотидами, плавающими вокруг в цитоплазме. Поскольку это действие происходит «скачкообразно» (каждый скачок — это сначала растаскивание цепочек и затем их воспроизводство), возникают короткие «паузы», заполняемые при помощи лигазы ДНК. Этот процесс повторяется снова и снова. Этот отлаженный трехэнзимный аппарат передвигается аккуратно по всей длине молекулы ДНК, пока ее цепочки не окажутся полностью разделенными и скопированными. В результате получаются две копии первоначальной ДНК.
Сравнение метода самовоспроизводства ДНК с квайнированием
Обратите внимание, что для энзимного воздействия на цепочку ДНК совершенно неважно, что информация для этого процесса хранится в самой ДНК; энзимы просто выполняют свои задачи по передвижению символов, точно так же, как правила вывода в системе MIU. Им совершенно все равно то, что в какой-то момент они копируют те самые гены, в которых закодированы они сами. ДНК является для них эталоном, лишенным собственного значения и интереса.
Это можно сравнить с тем, как Квайново высказывание дает инструкции по самовоспроизводству. Там у нас тоже было что-то вроде «двойной цепочки» — две копии одной и той же информации, одна из которых действовала как команда, а другая — как эталон. Процесс в ДНК отдаленно напоминает эту ситуацию, поскольку три энзима (эндонуклеаза ДНК, полимераза ДНК и лигаза ДНК) закодированы только в одной из цепочек, которая, таким образом, действует как программа, в то время как другая цепочка — всего лишь эталон. Это сравнение приблизительно, поскольку в процессе копирования обе цепочки используются как эталоны. Все же эта аналогия очень интересна. Существует биохимическая аналогия дихотомии «использование — упоминание»: когда ДНК используется как последовательность символов для копирования, она похожа на упоминание о типографских символах; когда ДНК диктует, какие команды должны быть выполнены, она похожа на использование типографских символов.
Уровни значения в ДНК
Цепочка ДНК имеет несколько уровней значения; это зависит от того, насколько велик кусок цепочки, который вы рассматриваете, и насколько мощен ваш «аппарат для расшифровки». На низшем уровне каждая цепочка ДНК содержит код эквивалентной цепочки РНК, и необходимой расшифровкой является транскрипция. Разделив ДНК на триплеты и пользуясь «генетической расшифровкой», можно прочитать ДНК как последовательность аминокислот. Это — трансляция (уровнем выше, чем транскрипция). На следующем уровне иерархии ДНК читается как набор белков. Физическое извлечение белков из генов называется «экспрессией генов». В настоящий момент это является наиболее высоким из доступных нам уровней значения ДНК.
Однако в ДНК безусловно имеются и более высокие уровни значения, которые различить труднее. Например, у нас есть все основания полагать, что в ДНК человеческого существа закодированы такие его характеристики, как форма носа, музыкальные способности, быстрота рефлексов и так далее. Возможно ли, в принципе, научиться считывать такую информацию прямо с цепочек ДНК, минуя физический процесс эпигенезиса — извлечения фенотипа из генотипа? Теоретически такое возможно, так как можно вообразить мощнейшую компьютерную программу, симулирующую весь процесс, вплоть до отдельных клеток, отдельных белков, каждой мельчайшей детали, участвующей в воспроизводстве ДНК, клеток… и так далее, до конца лестницы. Результатом работы такой программы псевдо-эпигенезиса было бы описание фенотипа на высшем уровне.
Существует еще одна (очень маловероятная) возможность может быть, нам удастся научиться читать фенотип с генотипа, минуя изоморфную симуляцию физического процесса эпигенезиса и пользуясь вместо этого более простым расшифровывающим механизмом. Это можно назвать «сокращенным псевдо-эпигенезисом». К сожалению, сокращенный или нет, псевдо-эпигенезис пока нам недоступен — за одним замечательным исключением. Тщательный анализ вида Felis Catus показал, что на самом деле возможно прочитать фенотип прямо с генотипа. Читатель, может быть, лучше поймет этот замечательный факт, рассмотрев следующий типичный кусок ДНК Felis Catus:
… САТСАТСАТСАТСАТСАТСАТСАТСАТСАТ …
Ниже показаны уровни считываемое ДНК вместе с названиями разных уровней расшифровки. ДНК может быть прочитана как последовательность:
(1) оснований (нуклеотидов) .... транскрипция
(2) аминокислот .... трансляция
(3) белков (первичная структура) .... генное выражение
(4) белков (третичная структура) .... генное выражение
(5) скоплений белков .... более высокий уровень генного выражения
(6) ???
.
. .... неизвестные уровни, значения ДНК
(N-1) ???
(N) физические, умственные и психологические черты .... псевдо-эпигенез
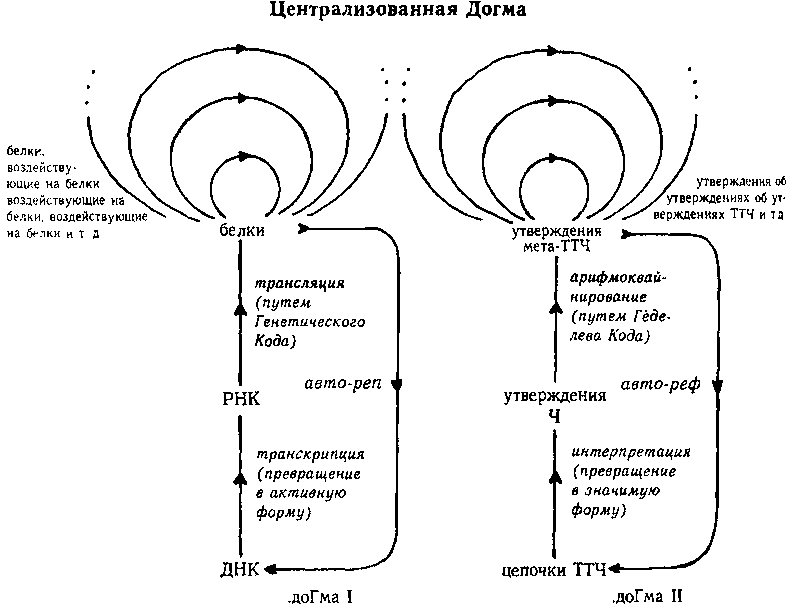
Центральная Догма
После этой подготовки мы можем приступить к рассмотрению детального сравнения между «Центральной Догмой Молекулярной Биологии» Ф. Крика (ДОГМА I) и «Центральной Догмой Математической Логики» (ДОГМА II), на которой основана Теорема Гёделя. Отображение с одной Догмы на другую показано на рис. 99 и на следующей схеме, вместе они составляют Централизированную Догму.
Обратите внимание, что А и Т (арифметизация и трансляция) образуют пары, также как G и С (Godel и Crick) Математической логике достается сторона пуринов, а молекулярной биологии — пиримидинов.
ДОГМА I ДОГМА II
(Молекулярная биология) (Математическая логика)
цепочки ДНК <==> строчки ТТЧ
цепочки мРНК <==> утверждения Ч
белки <==> утверждения мета-ТТЧ
белки, воздействующие на белки <==> утверждения об утверждениях мета-ТТЧ
белки, воздействующие на белки, воздействующие на белки <==> утверждения об утверждениях об утверждениях мета-ТТЧ
транскрипция (ДНК=>РНК) <==> интерпретация (ТТЧ => Ч)
трансляция (РНК=>белки) <==> арифмоквайнирование
Крик <==> Гёдель
Генетический Код (произвольное соглашение) <==> Гёделев Код (произвольное соглашение)
кодон (триплет оснований) <==> кодон (триплет чисел)
аминокислота <==> символ ТТЧ, процитированный в мета-ТТЧ
авторепродукция <==> автореференция
клеточная система автономии, достаточно мощная, чтобы позволить авторепродукцию <==> арифметическая формальная система, достаточно мощная, чтобы позволить автореференцию